handleiding
Niet HTML bestanden blokkeren voor zoekmachines.
door in WordPress theming
Niet HTML bestanden blokkeren voor zoekmachines.
Het kan voorkomen dat je als webmaster wil dat bepaalde bestanden niet worden geïndexeerd door zoekmachines als Google. Vele webmasters zijn bekend met de robots termen, maar hoe zorg je er voor dat een specifiek bestand zoals .doc of .pdf niet geïndexeerd wordt door de zoekmachines? In deze blog leggen we stap voor stap uit hoe je dit kunt voorkomen.
Er zijn twee verschillende richtlijnen voor je website: Crawl richtlijnen en index richtlijnen.
Robots.txt
Het robots text bestand wordt gebruikt om zoekmachines specifiek aan te geven wat ze niet of juist wel mogen doorzoeken in je website. Hiermee kun je inhoud verschuilen voor de zoekmachines. Het kan echter voorkomen dat bepaalde pagina’s of bestanden niet mogen worden doorzocht, maar dat ze alsnog verschijnen in de zoekresultaten. Dit kan bijvoorbeeld wanneer er links vanaf externe websites linken naar je pagina of naar het bestand.
Robots Meta Tag
Met de robots Meta Tag heb je de controle over hoe je individuele pagina’s wilt laten indexeren en hoe je ze wilt tonen in de zoekresultaten. De Robots Meta Tag wordt meegegeven in desectie van je pagina. Beide opties kun je dus gebruiken om inhoud te blokkeren voor de zoekmachines. Het is voor de meeste webmasters een koud kunstje om een pagina te voorzien van bijvoorbeeld een no-index tag. Hier gaan we in deze blog dan ook niet verder op in, maar hoe voeg je een X-Robot tag toe aan bijvoorbeeld een pdf bestand?
Wat is de X – Robot Tag?
Het grote voordeel van X -Robot Tags ten opzichte van robot meta-tags is dat je ze kunt toevoegen op niet -html bestanden zoals: PDF, Word, video of Flash bestanden. De X-Robot tag kan gebruikt worden als een element van de HTTP header reactie voor een bepaalde URL van een bestand of wegpagina.
In de volgende stappen gaan we in op hoe je een X – Robot Tag kunt toevoegen aan een specifiek bestand.
X – Robot Tag toevoegen aan een bestand
Het toevoegen van een X – Robot tag aan een bestand gaat op server niveau via het .htacces bestand.
Open het .htacces bestand van je website en voeg de volgende code toe aan je .htcacces bestand:
header set x-robots-tag: noindex
Sla je .htacces bestand op
Wanneer je meerdere bestanden wilt toevoegen kan dat op de volgende manier:
header set x-robots-tag: noindex
Het uitlezen van de http header in je PDF bestand.
Uiteraard wil je nu weten of je PDF bestand de juiste Tag heeft meegekregen. Dit kun je uitlezen op de volgende manier.
- Open Google Chrome en ga naar de de url van je PDF bestand.
- Klik rechtermuisknop in je PDF bestand en kies voor element inspecteren
- Ga naar de instellingen tab en vink de optie Disable Cache (while DevTools is open) aan. Hiermee voorkom je dat Chrome gecashte gegevens meestuurt waardoor je de http header niet juist kan uitlezen.
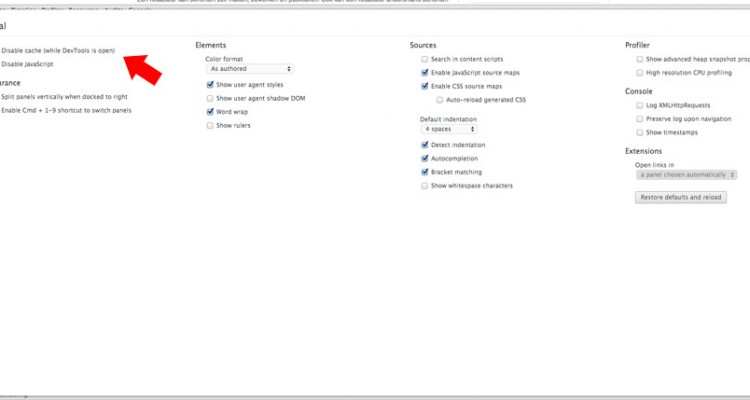 Het uitlezen van de http header in je PDF bestand.
Het uitlezen van de http header in je PDF bestand.- Na het aanpassen van deze instelling inspecteer je het PDF element opnieuw en ga je naar het kopje Network.
- Refresh de pagina en klik het PDF bestand aan.
- Wanneer je de x-robot-tag juist hebt toegevoegd zie je deze nu verschijnen onder het kopje Headers – Response headers.
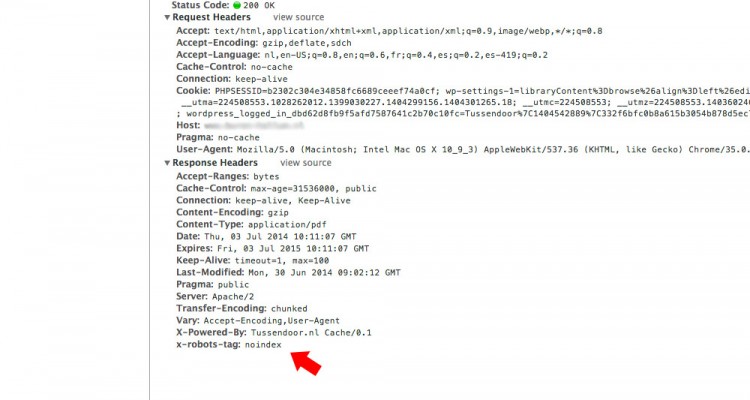 Het uitlezen van de http header in je PDF bestand.
Het uitlezen van de http header in je PDF bestand.Hiermee voorkom je dat een PDF bestand wordt meegenomen in de zoekresultaten van de zoekmachines.
Controleer na het aanpassen van de .htacces file altijd je website, want je zult niet de eerste zijn die per ongeluk alle niet html bestanden of een gehele site blokkeert ;). Mocht je nog vragen hebben over de X – Robot Tag? Laat dan gerust hieronder een reactie achter.